This has been a little side proof-of-concept project derived from our big ICLR publication. Turns out learning visual representations in a self-supervised manner with a temporal coherence loss can explain the phenomenon of color constancy.
[1] M. R. Ernst, F. M. López, A. Aubret, R. W. Fleming and J. Triesch, “Self-Supervised Learning of Color Constancy,” 2024 IEEE International Conference on Development and Learning (ICDL), Austin, TX, USA, 2024, pp. 1-7, doi: 10.1109/ICDL61372.2024.10644375.
 means that for any finite batch of function values
means that for any finite batch of function values  , where
, where ![\mathbf{f} = \left[ f(\mathbf{x_1}, ..., f(\mathbf{x_n}))\right] \sim \mathcal{N}(\mu, K)](https://www.markusernst.org/wp-content/ql-cache/quicklatex.com-eb4f409d8ec133a700fcfcfacc948440_l3.svg "Rendered by QuickLaTeX.com") holds.
holds.![\begin{equation*} \left[ {\begin{array}{c} f \\f^* \end{array} } \right] = \mathcal{N}\left( \mu, \left[ {\begin{array}{cc} K + \sigma^2 \mathbb{I}_n & K_* \\K_*^T & K_{**} \\ \end{array} } \right] \right). \end{equation*}](https://www.markusernst.org/wp-content/ql-cache/quicklatex.com-cb2057e43992e88a87091fb8df55e706_l3.svg "Rendered by QuickLaTeX.com")
 part at the top left in the kernel-matrix above.
part at the top left in the kernel-matrix above.
 with
with  the lengthscale and
the lengthscale and  the signal variance. But feel free to try out another kernels, like Brownian
the signal variance. But feel free to try out another kernels, like Brownian  for example.
for example. and a variance
and a variance 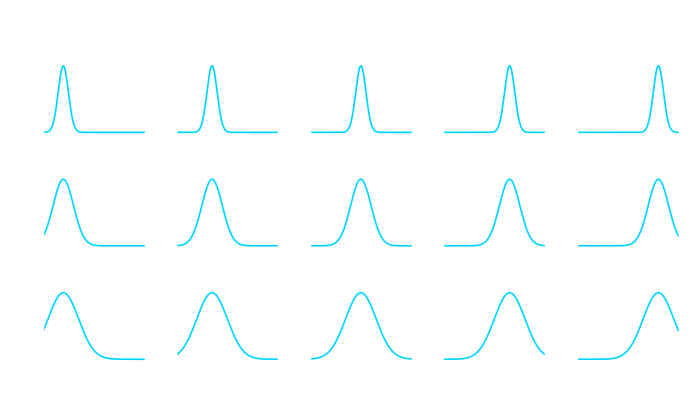
 with values
with values  ,
,  with noise in each point
with noise in each point  and points
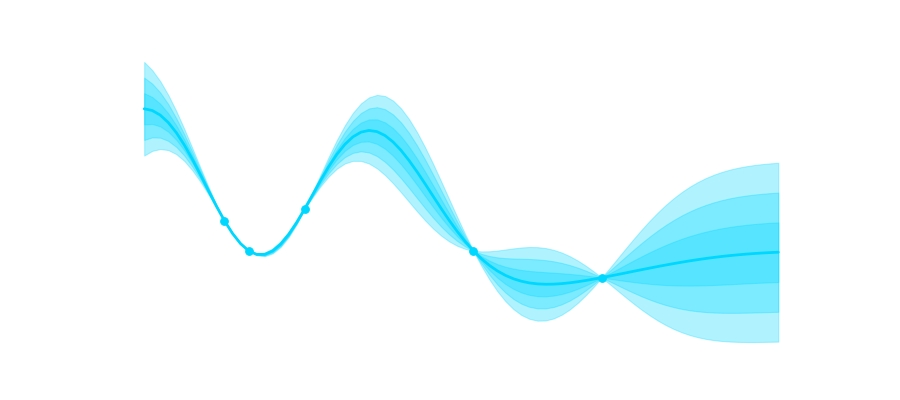
and points  for which we want to predict the output, adapting our probability distribution leads to:
for which we want to predict the output, adapting our probability distribution leads to: , with
, with


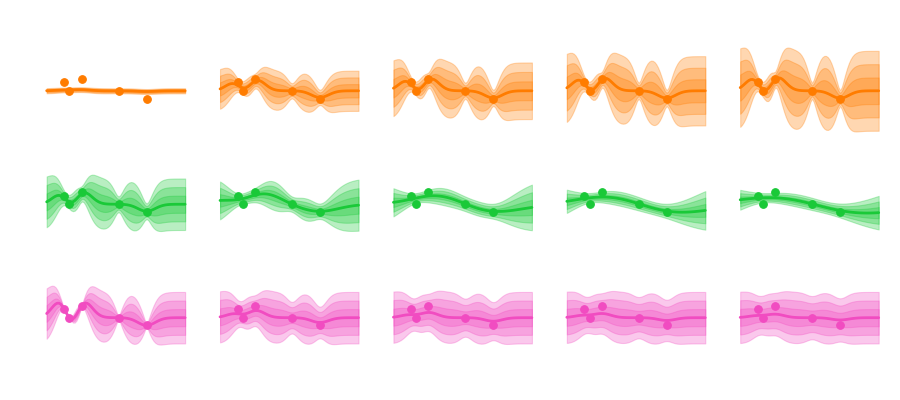
 and the noise that can influence how we model our data. Varying these parameters looks like this:
and the noise that can influence how we model our data. Varying these parameters looks like this: